CI/CD/CD, Oh My!
- 21 minutes read - 4305 words - Page SourceSince leaving Amazon ~4 months ago and dedicating more time to my own personal projects (and actually trying to ship things instead of getting distracted a few days in by the next shiny project!), I’ve learned a lot more about the Open Source tools that are available to software engineers; which, in turn, has highlighted a few areas of ignorance about CI/CD Pipelines. Emulating Julia Evans, I’m writing this blog both to help lead others who might have similar questions, and to rubber-duck my own process of answering the questions.
Preamble
If you are an experienced developer who’s familiar with CI/CD and GitOps, and/or you are someone I’ve sent this post to in the hopes you can help answer my confusions, you probably want to skip ahead
What are CI/CD Pipelines1?

CI/CD Pipelines are software development tools that automate everything between “a proposed code change is approved and submitted” and “the resultant change is running on user-facing systems”. Basic functionality includes building the change (converting from “human-readable code files” to “optimized machine-executable instructions”) and deploying the built artifact to user-facing systems (to “production”); more sophisticated pipelines will include various stages of testing, automatic rollbacks if issues are detected post-deployment2, and integration with other functionality like notifications, monitoring, logging, and reporting.
The practice of making this process smooth and frequent is commonly called “CI/CD”, for “Continuous Integration/Continuous Deployment”. Moving from a deployment cadence where new releases are deployed every month (or longer!), to one where each small change is made available within minutes of the code change, has numerous benefits:
- Each deployment is associated with a smaller change - if any post-deployment issues are encountered then it is easier to track them down (and rolling back that deployment will not impact any other features).
- Merge conflicts (situations where two developers are trying to change the same code, and human judgement is required in order to determine the correct end-state) are, ceteris paribus, simpler to resolve when smaller changes are being made.
- Users get benefit from new features earlier if they don’t have to wait for the monthly release cycle, and developers get feedback earlier in the development cycle.

But what is CI/CD?
Without going into too much detail (because I’m not sure how much detail I can share!), Amazon Pipelines3 was well-integrated into the existing tooling (Package Templating, Code Repositories, Build Fleet, Deployment Systems) in a very standardized way, such that the “standard” CDK package generated for a Service would define a great starter pipeline that hit most of the Best Practices, and adding features to it (new deployment environments, new tests, new packages to be built, etc.) would normally only take a few lines of intuitive CDK code. The fact that the pipeline itself was defined in code meant that you got to apply all the best features of Code Management (Code Review, rollback, extraction of common patterns to helper functions, to name but a few) to the management of the pipeline - it became a first-class member of the service infrastructure4.
As I’ve explored Open Source solutions, I realized that I never considered the distinction between CI and CD (since Pipelines and associated systems abstracted all that away by magic). In fact, there are two practices referred to by CD. There are lots of opinions on them5, but general consensus appears to be:
- Continuous Integration: As soon as a code change is pushed, it is built, tested6, and merged ("integrated") into the codebase7, so that other developers can pull that change to keep their snapshot of the codebase in-sync.
- Some descriptions of CI (like Docker’s) include “the image that results from a build is pushed to an image respository”; others (like Red Hat’s) place that responsibility in Continuous Delivery. Since high-level descriptions of CI tend to focus on ensuring that a developer’s code changes are integrated into the code repository, I’m inclined to side with Red Hat and have CI declared complete once a proposed code change has been checked-in and tested.
- Note that, in an ideal developer experience, tests should be run both at the time of code review (so that reviewers don’t waste their time on code that would fail tests when pushed), and also immediately after push (to ensure that any other apparently-innocuous changes that were pushed between review-time and push-time didn’t change this revision’s behaviour)
- Continuous Delivery: automates the process of deploying a built-image to test/staging environments8 and execution of any tests that require deployment. For each change, once this process is complete, deploying the change to production with confidence should be as simple as pressing an approval button.
- Continuous Deployment: builds on Continuous Delivery, by introducing enough pre-production testing and rollback-safeties that it is considered safe to deploy an approved change to production without manual approval. Make the button click itself!
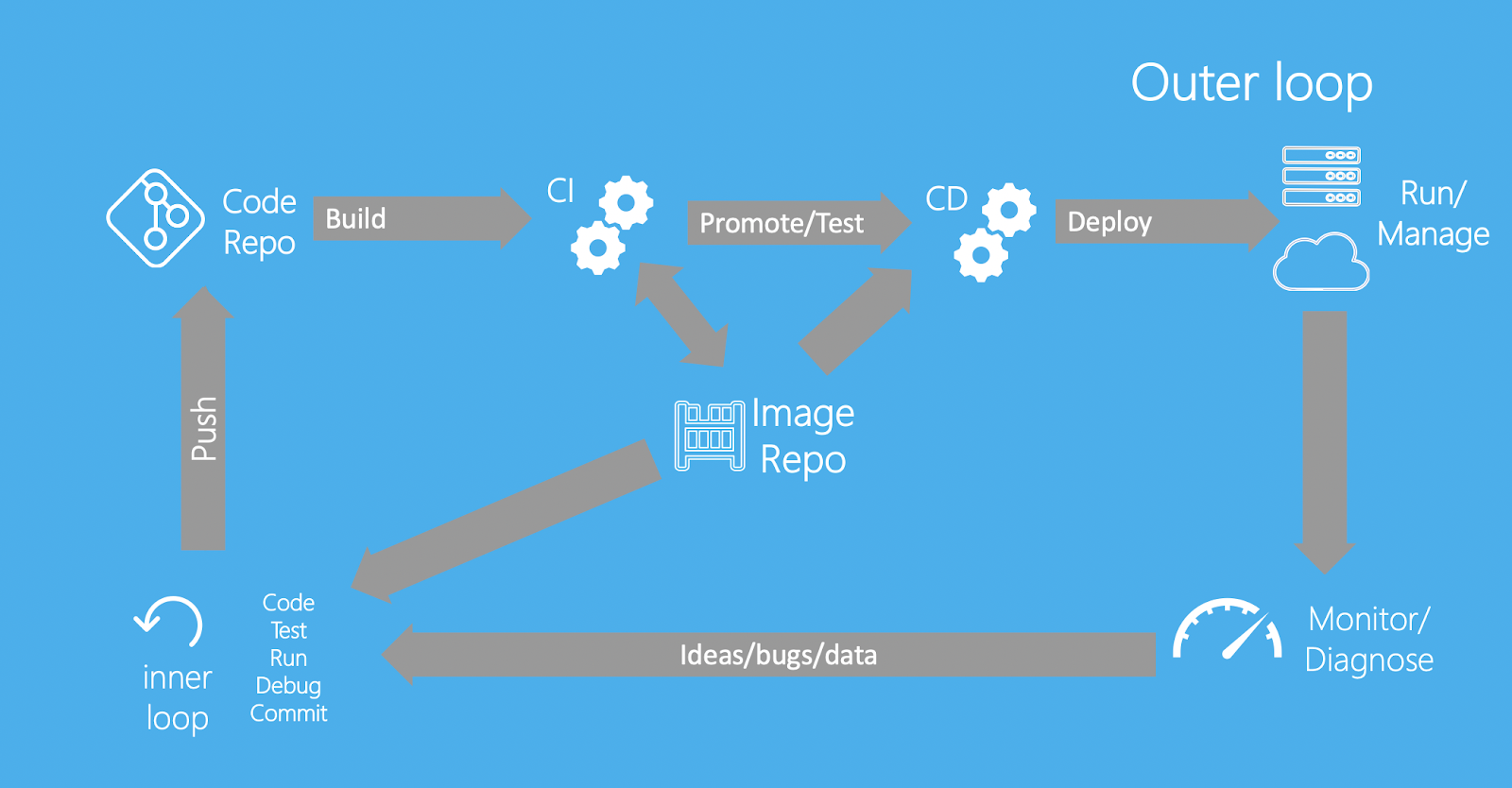
However, the descriptions of CI seem incompatible with the tools it is used to describe. Unanimously, descriptions of CI agree that CI ends at-or-immediately-before the point that an image is pushed to an image repository - but systems like Drone CI are often used to build pipelines that also deploy (e.g.), and in fact all of the “CI” systems listed here both seem capable of, and are often used for, extending the pipeline beyond “build, test, merge” and on to “deploy to env, test on env, repeat”9. I think that the best way of resolving this incongruity is by recognizing that there is no such thing as “a CI tool” - rather, CI/CD(2) are practices, and there are tools that help with those practices, with some tools specializing (not necessarily uniquely) in some areas.
Of course, this is pedantry - I wouldn’t call someone wrong for describing something as a “CI tool”, and indeed I refer to “CD tools/systems” below (which appear to be more specialized - that is, “CI” tools can trigger CD, but CD tools seem to only “do” CD) - but the distinction helps me get it straight in my own head. If you think I’ve misunderstood this, please do let me know!
{kind=link}
GitOps
(For the avoidance of doubt - here, I’m talking about a pipeline that deploys to a web service, and that is triggered by changes to code packages that are controlled by the team that owns that service. In such a situation, I claim that, in the spirit of CI/CD, you should want any code that passes all tests to be deployed as-quickly-as-possible (but no faster!) to all environments. There are certainly reasons why you might want to be more cautious about changes to dependency packages not controlled by your team, or if you are “deploying” a change to client applications rather than to a service you own)
Poking around with Open Source CI/CD introduced me to a term for a thing I’d already been doing - GitOps, a practice whereby the definition of an application (including infrastructural definition) should be defined in a Version Control System repo (probably, but not necessarily, using Git), and that changes to that repo should automatically (via CI/CD!) result in changes to the deployed application.

So far, so uncontroversial - storing source code (whether application code, or architectural definition code) in VCSs has many benefits (CR, gradual-rollout with testing, rollback, persistence, inspection, composability, etc.). In particular, configuration changes (which, famously, are responsible for a disproportionately-high number of incidents, given how apparently-innocuous they are) can benefit from the same management and safe-rollout systems as traditional code10. This practice of fully defining systems in Version-Controlled code was very much the norm in Amazon, too - and, in systems where it wasn’t, prioritizing the move to this practice was generally accepted. What confused me is GitOps’ pattern for releasing new versions of Application Code.
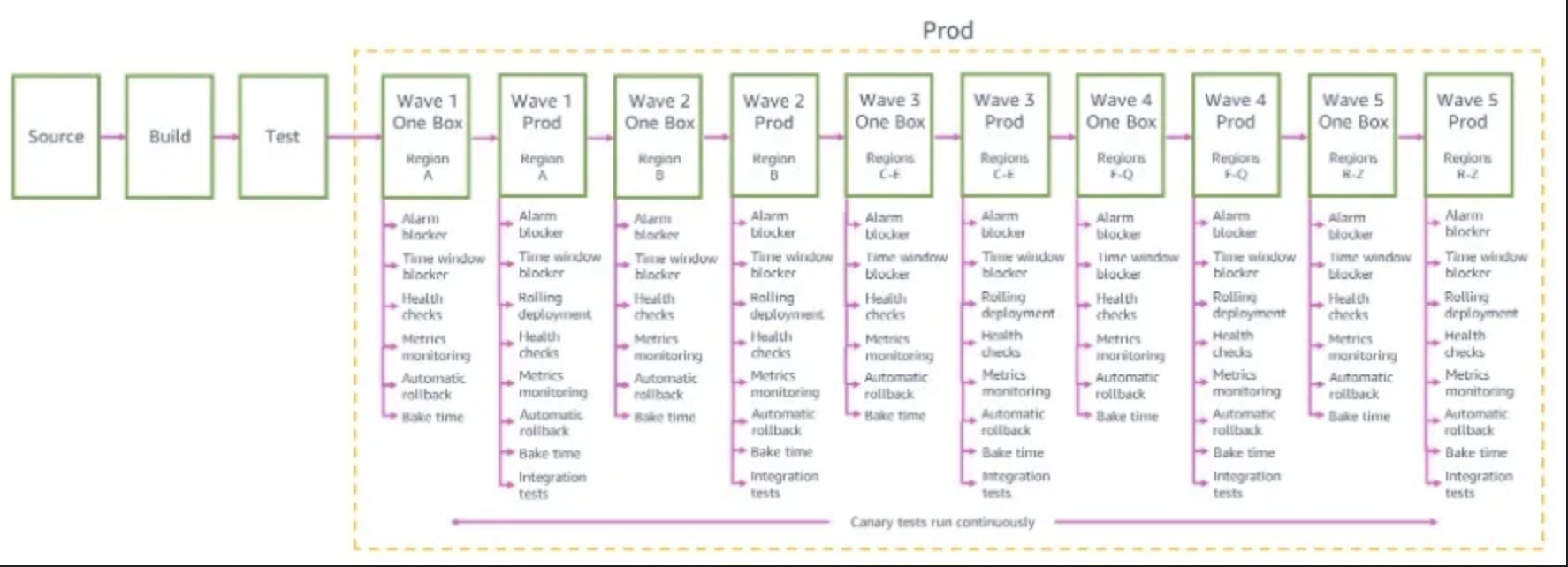
In Amazon Pipelines world, both the Application Code and the Infrastructure Code would be managed in a single pipeline11. When a change to either12 was approved, the change would get built and tested, and a Version Set Instance (an Amazon-internal concept that can be thought of as analogous to an Image in most meaningful ways, even though the format differs - it’s a deployable artifact that snapshots the version of the package and all of its transitive dependencies) would be created. The Pipeline would then kick off, sequentially repeating:
- Check for any deployment blockers for the upcoming promotion (e.g. “Don’t deploy outside of business hours”, “don’t deploy during the one-week period before Re:Invent”, or “don’t automatically deploy if there’s an active High-Severity Issue” - as the last one hints, of course any blocker can be manually overriden if necessary!).
- Promote the Version Set Instance to the next stage of the Pipeline13. This will almost-always result in a deployment of the VSI to some compute resources, but not always - sometimes a stage is configured just to execute some finite job (e.g. bundling up some resources and exporting them to an S3 bucket) rather than to update a running service.
- Run any post-deployment checks. These might include user-impersonating tests that call the service’s external network interface, load tests that drive synthetic traffic to the system and monitor its performance metrics, or “bake tests” that wait a given period of time and ensure that metrics stay within specified parameters.
Three key points to note here:
- The single application pipeline (managing both App Code and Infra Code) can be triggered by changes to multiple packages.
- The definition in the Infrastructure repo of “What Application Code should be deployed to environments?” only defines what package(s) should be deployed, not the versions of them. This is because…
- …the state of “which version of the App Code is deployed to which environment at a given time?” is a property of the pipeline, not of any external store. It can be queried from the pipeline system (e.g. for diagnosis of incidents, decoration of dashboards with “deploy timelines”, etc.), but the pipeline is the “Oracle” which both decides (by taking input from “was there a new push to a source repo that should trigger another wave of promotions?”, “are there promotion blockers active?”, “what is the state of the post-deployment tests for a given environment?”, “have there been any rollbacks triggered?”, etc.) and answers that question
This final point is true because the interaction between Pipelines and the deployment systems took the form of an API call - when Pipelines determined that it was time for an environment to update to a new version, it called the deployment system to trigger a deployment. In contrast, OSS CD tools that I’ve looked into (ArgoCD and Flux) seem to default to triggering a deployment based on a change to a source Git repo, rather than via an API call14 - when they detect that the state of the application differs from the intended state defined in the Git repo, they make a deployment to change to the desired state. This means that, in order for a change to App Code to result in a deployment that updates an environment to use that code, the flow would be:
- New commit pushed to AppCode repo
- CI pipeline detects that push, kicks off build->test->image-push, noting the tag of the image
- A stage in the CI pipeline creates an automated commit in the InfraCode repo, updating some configuration file to state “the image deployed to stage N should be [image-tag]”
- CD system detects that new commit, and carries out a deployment
This…works? I guess? But I’m confused about why the intermediate step of “make an automated commit to the Infrastructure repo” is considered desirable. To me, this seems like it would “dirty” the Infrastructure commit history with a bunch of “Updated Foo Stage to Bar image” commits15, as well as require adding a conceptually-strange write-permission of the Pipeline “backwards” to a source-code repo (subjective-opinion hand-wave alert - Pipelines should read from source code repos, not write to them!), and I cannot conceive of any advantages that hold up under scrutiny:
| Claim | Counter-claim |
|---|---|
| Writing updates to deployment-intention updates into a Git repo provides an authoritative point-in-time record that can be easily consulted when diagnosing historical data | 1. No it doesn’t. It provides a point-in-time record of when the intention was updated, but the actual deployment might be delayed if there are issues with the CD system or its connection to the Git repo. The only truly authoritative record of “what was deployed when” is the CD system itself16. In a setup where a Pipeline calls an API to trigger a CD deployment, and can poll for success/failure (or discrepancies), the Pipeline itself is a reliable source.
2. Even if the Git repo were a trustworthy reflection of the state of the system, it seems that an API (such as presented by the Pipeline or the CD system) would be a much “friendlier” interface for consuming “what was deployed when” than a Git repo. In particular, if using this deployment information to annotate a dashboard with vertical lines representing deployments, I imagine the dashboarding system would find it easier to consume the response from an API than to consume a Git log17 |
| Git is a universal and open standard, meaning that multiple OSS CD systems can consume it | Git is a universal standard, but “how to define what image should be deployed where” isn’t (at least, as far as I know). If you’re going to standardize image<->env mapping definition in VCS files, you could just as easily [citation needed] standardize an API communication between Pipelines and CD systems to define what should be deployed to where (as the next row will show, it’s probably preferable for this to primarily be poll-based rather than push-based, though both methods would be useful) |
| If the Pipeline sends a message telling the CD system to update, that request might get dropped, leading to inconsistency. Polling a Git repo will ensure the CD system never “misses” an update | We have decades of research in how to ensure consistency between networked systems; and although some of the problems are extremely tricky, this doesn’t seem like one. I’m not a PhD, but it seems that having the Git repo poll the API provided by the Pipeline (and, optionally, consume push notifications for “faster” updates) would be just as good as the Git-polling example |
| Storing the image<->env mapping externally to the Pipeline means that it is possible to “cold start” a new Pipeline (potentially, using a different CI system) without any inconsistency | That’s….true, I guess? But a) how often would that happen, and b) in such a situation, couldn’t you easily achieve consistency by running a no-op change through the Pipeline to “flush” it? |
My questions and confusions
If you jumped straight to this section, the links on the questions link back to the sections where I explore the questions in more detail.
- Where is the distinction between CI and CD? - given that descriptions of CI seem to have it end at the point that code (or it’s resultant image) is tested and pushed to a repository, why is it that “CI” tools are commonly used to define pipelines that extend beyond that point - to deployment and on-env testing?
- Is it perhaps the case that CI is a practice, and calling something a “CI” tool implies only that it helps with that practice, not that it should only be used for that practice? That is, a CI tool can create a pipeline which results in deployment (typically by triggering a specialized CD tool)?
- Why does GitOps define the deployed-image in a Git repo? - as opposed to having the Infrastructure Code define what packages should be deployed to which Infrastructure elements, and letting the Pipeline decide which Application Code revisions should be deployed - the latest revision that has passed all preceding tests, modulo any rollbacks. The GitOps way seems to introduce a lot of “image-updated” commits to the infrastructure repo, and requires the Pipeline to have otherwise-unnecessary write-permissions to that repo, for no real advantage that I can see.
- Again, I want to stress the humility with which I ask this question. I would not for a second believe that, after less than a month of tinkering with OSS CI/CD systems, I’ve come up with a better paradigm than the entire community - rather, I’m trying to highlight the fact that my expectations differ from the tools’ defaults, which suggests that I’ve missed some advantage of their approach.
(2022-10-27) Update
I created a Drone plugin that can be used to write content (such as the image-tag that should be used in a given stage) into a file and commit that change into a Git repo, thereby reproducing the behaviour I expect from a CI/CD pipeline. It works! But the fact that I had to craft this by-hand, again, suggests that I’m doing something that OSS folks consider wrong.
-
Thanks to this post for teaching me how to do image captions easily in Hugo! I still haven’t figured out how to get footnote links to properly render within them - this post discusses it in the context of shortcodes, not partials (I can never remember the difference…). I tried piping it through
markdownifybut that did nothing. Ah well… ↩︎ -
To make it safe to deploy on Fridays - even though you shouldn’t do it, no matter what pithy catchphrase Charity or Lorin tweeted out without explanation. ↩︎
-
Note here I’m talking about the Internal tool “Pipelines”, not the CDK service AWS CodePipeline! Though I suspect that, under-the-hood, the former is a usability and compatibility wrapper over the latter ↩︎
-
Admittedly, there are some use-cases that Amazon Pipelines didn’t serve well, as out-lined by my ex-colleague in replies under here. With all due respect to Keith (whose experience is deeper, broader, and longer than my own), a lot of those issues sound like “trying to use Pipelines for something it’s not intended for”. I will freely admit that I must have misunderstood a lot of the criticisms, since they are contrary to my own understanding of what Pipelines can/does do (1, 2, 3); but the points that I definitely did understand (it’s hard to use build systems that aren’t in the pre-defined list or to have separate builds against separate base images) seem to fall pretty solidly in the category of “…well don’t do that (on Pipelines), then”. Plenty of client-app developers, for instance, have set up their own off-Pipelines CI/CD systems because they have needs that don’t mesh well with Pipelines’ paradigm (which is very Services-on-AWS-centric). That doesn’t make Pipelines a bad system: it just means that it (intentionally) made the trade-off to support fewer use-cases, with those supported use-cases being easier and smoother. This makes sense in the context of an internal tool that can be reasonably expected to only support a few “blessed” use-cases (and which, implicitly or explicitly, intends to constrain users to only interacting with blessed repositories, tools, and licenses for InfoSec/Legal reasons). In summary - "If judged by the criteria of an OSS system, Pipelines would be deficient because of its limitations - but corporate systems have different priorities" ↩︎
-
If you get 3 developers in a room and ask them for definitions of what constitute the categories of testing (unit/component/acceptance/integration/smoke/regression/stress/…), you’ll get at least 5 different answers. Suffice it to say that, from context, it seems pretty clear that CI should only execute tests that don’t require a code artifact to be deployed to an environment or to serve requests - in my experience, these are usually called Unit and/or Component Tests. Please do not feel the need to espouse your preferred taxonomy in the comments :) ↩︎
-
In a Trunk-based development flow, the phrase “as soon as the code is pushed, it is[…] integrated into the codebase” does not make much sense, since developers push directly into the codebase. Instead, this should be read as “as soon as a proposed change is approved, it is[…]”. In GitHub this direction is reversed again, since a developer will push to their own repo and then make a Pull Request asking the main repo to Pull their change in. This has always struck me as an unnecessary level of indirection - why do you need to fork a repo on the server to offer to contribute code, why can’t “Push Requests” live independently of a server-based repo? But I digress… ↩︎
-
Contra recent trends…do not, as they say, get me started. This would be a whole blog post in itself, and this one’s already too long. A generous reading of this opinion is that it means that Big Tech doesn’t have environments specifically for manual testing (humans clicking around and checking that things are as-intended), which is perfectly reasonable. But the naïve reading (which should always be considered) - that there’s no need to do pre-production on-env testing, or even that all pre-production on-env testing is done on production via feature-flags and weblabs - is both false, and harmful to promulgate. That’s an ideal to move towards, for sure - but they’ll always be value in having a fully blast-radius-secured environment where it’s safe to test-to-destruction in the knowledge that you cannot possibly affect customers. ↩︎
-
Admittedly, sometimes the actual deployment is handled by a dedicated system like CodeDeploy, Argo, or Flux - but it is triggered by a pipeline defined in a “CI” system. ↩︎
-
One of my more opinionated and widely-linked
rantsposition papers on the Amazon Wiki was an in-depth response to the common request from managers for a way to change business configuration (as opposed to operational configuration, which might need to be manipulated directly in an emergency during an incident) in a way that took immediate effect. It outlined the advantages of using the tooling that already exists for coding, and asked them to balance the cost of building parallel replicas against the benefits of making changes with a reflection time of seconds instead of minutes. ↩︎ -
In practice, an app’s Application Code would quickly grow beyond a single package, and in some cases the Infrastructure Code would do so, too. This isn’t relevant for our purposes - where I refer to “a change/push to the App Code package”, feel free to mentally substitute “…to any of the packages that define the App Code”, etc. ↩︎
-
Typically, but not always, authored by the owners of the application; but always approved by them (either manually, or via automated systems which auto-approve predictable trivial changes that pass basic validation and automatic testing - typically, configuration changes). In particular, this means that a pipeline-execution would not be started for any updates to dependency packages that the application consumes but that the team does not own. There was a separate mechanism for merging these dependency-updates into the Version Set, which is not relevant to this discussion. ↩︎
-
Which, remember, is defined in the Infrastructure package. Except in extremely unusual circumstances, the first deployment stage of a Pipeline would be a self-mutation stage, that would update the Pipeline itself if necessary - e.g., if new deployment stages or post-deployment tests have been added. ↩︎
-
I should stress that I’m only a week or so into my investigation of CD systems - it does look like it’s possible to set Parameters on a CD configuration which can be updated by API call, which would recover the Amazon-Pipelines-like behaviour if such a parameter is used to record the intended-deployed-image. My purpose in making this post isn’t to complain that I can’t do what I want (/am used to) - it’s to understand why the default chosen by these systems is different from what I expect, since it suggests that people smarter and more-experienced than me have determined that default to be “better” in some way. I want to understand those advantages! ↩︎
-
Or, I guess, you could extra the “which images on which stages” configuration to a standalone repo. But, still - extra complexity, and for what? ↩︎
-
Assuming that the CD system is the only entity with permissions to make deployments to the managed system - that is, no “out-of-band” deployments can be carried out. If an out-of-band deployment were carried out, the CD system would quickly detect the discrepancy and correct it - but, for a short amount of time, there would still be a discrepancy unrecorded in the CD system’s view of the world. ↩︎
-
In actual fact, an even better solution for dashboard annotations would be to have the metrics emitted from the system themselves provide metadata about the deployed image, which can be overlaid onto the dashboard - but a) that’s not possible in less-sophisticated dashboarding systems, and b) this is just an illustrative example, I’m sure there are plenty of other situations where a consuming-system (rather than a reading-human) would “prefer” to consume an API response than a Git log. ↩︎